Another 5 Things to Know About Meta-Analysis

 Last year I wrote a post of “5 Key Things to Know About Meta-Analysis”. It was a great way to focus – but it was hard keeping to only 5. With meta-analyses booming, including many that are poorly done or misinterpreted, it’s definitely time for a sequel! [And now there’s a prequel on the data, too.]
Last year I wrote a post of “5 Key Things to Know About Meta-Analysis”. It was a great way to focus – but it was hard keeping to only 5. With meta-analyses booming, including many that are poorly done or misinterpreted, it’s definitely time for a sequel! [And now there’s a prequel on the data, too.]
Meta-analysis is combining and analyzing data from more than one study at a time. Using a variety of statistical methods, some of which were purpose-built, you can condense a vast amount of information into a single summary statistic.
In last year’s post, I explained the basics, and concentrated on some ways to see the value of a meta-analysis.
This time, I’m pointing to some common traps.
1. A meta-analysis is a safer starting point than a single study – but it won’t necessarily be more reliable.
A meta-analysis is usually part of a systematic review. It’s a heavy-duty effort, and it’s often described as the ultimate study, outweighing all others. The last word. A single study becomes a puny thing, to be ignored even.
But while combined results can carry a lot of weight, there are 3 main problems with the idea that a meta-analysis always trumps a single study.
Firstly, a systematic review and meta-analysis isn’t a formal experimental study. It’s a non-experimental or descriptive study. There are subjective judgments every step of the way, giving small teams of like-minded people plenty of room to steer in a desired direction if they want to. A bad or patchy meta-analysis might not come to as reliable conclusions as a well-conducted, adequately powered single study.
Secondly, it’s not at all unusual for a meta-analysis to be heavily dominated by a single study. A study by Paul Glasziou and colleagues in 2010 found that even when there were several trials, the most precise one carried on average half the weight of the results – and around 80% of the time the conclusion of the meta-analysis was pretty much the same as that single study. Understanding and discussing that dominant study is critical.
Let’s look at an example. Some background first: the figure below is a forest plot of a single meta-analysis from within a systematic review. I’ve written a quick primer on understanding these here.
Each meta-analysis doesn’t just add studies up. It arrives at a weighted average, taking into account size of the study, for example. This forest plot shows you the weight each of 6 studies is contributing to the result (the line in bold – click to see a bigger version). And one trial – the HF-ACTION trial – accounts for just over 70% of the result. It’s not that the other studies don’t matter – we’ll come back to that later. But they don’t really change this result dramatically. (In the 2010 version of this meta-analysis, the HF-ACTION trial was even more dominant, weighing in at 78%.)
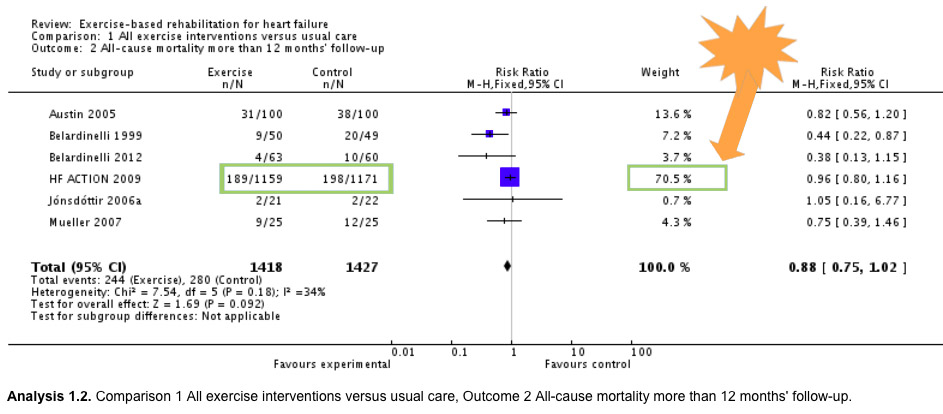
The third problem is so big, it gets the next place on this listicle: a single new study can overturn the results of a meta-analysis. As soon as the results of HF-ACTION were available, it was, on its own, a more reliable source on many questions than previous meta-analyses.
2. A meta-analysis is a snapshot in time – it can even be out-of-date the day it’s published.
Research in many areas grows very rapidly. Most meta-analyses are out-of-date – and that process is speeding up. Even a decade ago, though, some were out-of-date when they were published, and the median “survival” time for a systematic review was 5.5 years.
Take our heart failure example. Before the HF-ACTION trial published in 2009, the picture was different. With a much smaller pool of data, some were convinced that exercise-based programs were reducing mortality. But the uncertainty was too great for many, who remained concerned that exercise could be too risky for people with heart failure. What’s more, there was very little data available for women with heart failure. (28% of the participants in HF-ACTION were women, which was a big addition of data!) Meta-analysts moved fairly quickly when HF-ACTION arrived, but that’s not usually the case.
When there’s a new study, you really need to be able to put it into perspective. And an existing meta-analysis can help you do that. Sometimes, a new study includes an updated meta-analysis too, which makes life very easy! But if you’re looking at a meta-analysis that’s not very recent, you still need to be looking at later single studies as well. (That’s a big topic for another time!)
 3. Look carefully before you take an outcome literally – it may not be what it appears to be.
3. Look carefully before you take an outcome literally – it may not be what it appears to be.
When we consult research for answers to our own questions, translating researchers’ conclusions can be a very tricky business. The elements that go into determining what’s measured in a study are complex. They’re related to the needs of good quality and/or feasible research – not necessarily the very specific questions we might have.
When it comes to meta-analysis, we’re bound by two things: what the original studies measured, and what techniques are reliable for meta-analysis. What the original studies measured may have much to do with getting a study done in as short a time as possible. Surrogate outcomes and biomarkers are critical, but they can lead to jumping to premature conclusions. (More on that here.)
And don’t take a description like “cardiac event” for granted: it might not mean what you think it means. It’s very common for trials – and therefore meta-analyses – to include composite outcomes with accessible, simple names, but complicated, convoluted meanings. So you really need to look at the fine print. (I’ve written more about that here.)
A meta-analysis can compound this problem, because those outcomes might have been more likely to be common among studies. That allows them to be pooled together in a meta-analysis easily. Don’t overlook the outcomes that could not be pooled together: they might even be more important to you than the ones in the meta-analyses.
 4. Not all studies belong together.
4. Not all studies belong together.
Sometimes systematic reviews don’t meta-analyze when they could. Often, though, you’ll see authors advise caution because of heterogeneity between studies that were pooled. When you see that, take the caution very seriously!
Pooling studies that shouldn’t be combined is one of the most common flaws you’ll see in meta-analyses. If the results are too picture-perfect consistent, that can be a bit of a worry if there’s not a definitely dramatic effect. It could mean that the groups of people who have been studied are too much alike – not really representative of the total population at all.
On the other hand, if the results are too inconsistent – what’s called heterogeneity – it could mean that the results should not have been meta-analyzed at all. Key here: can the heterogeneity be explained? For example, is it down to known differences in the people in the studies?
You can read about methods for measuring heterogeneity in meta-analyses here and here [PDF]. Rule of thumb: the I2 is a very common statistical measure for this – a result of 50% or more is starting to get high. (You can see the I2 in our example above down in the details on the bottom left: it comes in at 34%, which isn’t very high.)
Rule of thumb: you want to see some heterogeneity, but not too much!
5. Missing studies and missing data can torpedo a meta-analysis.
One of the reasons results can be too consistent is because all the bad news is missing!

Which brings us to the question of missing studies and missing data.
If studies in a meta-analysis have missing data – many people lost to follow-up for example – the authors need to tell you how they dealt with it. (Unfortunately, they might not though.) You can see how this can affect the results in my discussion of an example here.
But by far a bigger problem is when the results of studies have simply not been reported. Imagine, for example, where we’d be if the HF-ACTION investigators had not published their results. You wouldn’t think that could be a big problem, but it is. I have a quick look at the way meta-analysts try to check for unpublished studies here, and there’s detailed technical coverage of this complex and controversial area here.
The real solution, though, is for all studies to be published. And that’s something you can do something about! Find out more about the problem and what you can do to help solve it, here at the All Trials campaign website.
And if this has gotten a bit disheartening, re-visit the first 5 things to remember what’s great about meta-analysis!
~~~~

To find systematic reviews of interventions in health care, with and without meta-analyses, try PubMed Health. (Disclosure: Part of my day job.)
5 Tips for Understanding Data in Meta-Analysis
5 Key Things to Know About Meta-Analysis.
More from Absolutely Maybe on Meta-Analysis.
Want to study more about meta-analysis? Johns Hopkins has a free online introductory course, with certification.
The example of a meta-analysis dominated by the results of a single trial is Analysis 1.2 from a systematic review on exercise-based rehabilitation for heart failure by Rod Taylor and colleagues (2014).
The cartoons are my own (CC-NC license). (More at Statistically Funny and on Tumblr.)
* The thoughts Hilda Bastian expresses here at Absolutely Maybe are personal, and do not necessarily reflect the views of the National Institutes of Health or the U.S. Department of Health and Human Services.