The Mess That Trials Stopped Early Can Leave Behind


Many trials end with a whimper. But some end with a bang.
Press release, press conference, lots of fanfare – and backlash. The drama of another clinical trial being stopped early burst into public view this month. This time it was an NIH blood pressure trial called SPRINT.
Testing treatment aimed at a lower-than-usual blood pressure target against standard management was intending to be collecting data till October 2018. They’ve ended that after monitoring of interim results found a big difference in favor of aiming for lower-than-usual blood pressure. More on that later. But first let’s look at some examples that show why stopping any trial early is so controversial.
To start: a tale of 2 trials of a drug for secondary progressive multiple sclerosis (SPMS) (interferon beta-1b). One started in Europe in 1994; the other got underway in the US and Canada in 1995. The European trial stopped 2 years early after interim results “gave clear evidence of efficacy. Treatment with interferon beta-1b delays sustained neurological deterioration” – the first treatment found to do that for SPMS.
So what then for the North American trial, still in its early stages? The knowledge base providing the ethical justification for their trial had shifted – and they had hundreds of people on placebos. The trial had a data monitoring committee (DMC). The DMC has the role of protecting participants against harm and making judgments about the data during a trial. (A DMC is also called a data and safety monitoring board (DSMB) or data monitoring and ethics committee (DMEC).)
The DMC looked at their data, and decided to keep going. They stopped early, too, in November 1999 – not because of benefit. Unfortunately, there was no benefit on delaying disability. They stopped early for futility – the belief that the outcome wasn’t going to change if they continued. (If you want to brush up on the basics of stopping trials early, I’ve written a primer over at Statistically Funny.)
Where did that leave people with SPMS? Despite 2 trials, the picture was murky. It took another big trial that didn’t stop early to be sure. According to a systematic review in 2011, the evidence that interferon beta-1b doesn’t work for SPMS is “conclusive” (PDF). (The drug is not approved for the indication of SPMS by the FDA.)
That time, the reason the first trial came to an exaggerated impression seemed to be the number of patients who might not have fully progressed to SPMS.
Our next story is an example a few years later. This time the disease is a form of leukemia (AML), and the trial is testing 5 courses of treatment against 4 courses, to see if the burdens of extra toxicity and intensive treatment are worth it.
The study’s statistician, Keith Wheatley, and chair of the DMEC, David Clayton, tell the story of what happened. It was a Medical Research Council (MRC) trial in the UK, and the data in leukemia trials for those was monitored annually. The first set of data showed major benefit to 5 courses: there were only 7 deaths compared with 15 in the group having less treatment.
The DMEC “deliberated at length”, and decided not to recommend stopping the trial but to check the data again in 6 rather than 12 months. When it came, the benefit in favor of 5 courses had grown stronger: “Again, the DMEC deliberated long and hard and again concluded that recruitment should continue”.
When the trial finished as planned, there was no mortality benefit from the extra course of treatment. The figure below shows what happened as the trial moved to its final tally: 157 deaths in the group having extra treatment compared with only 140 in the other group.
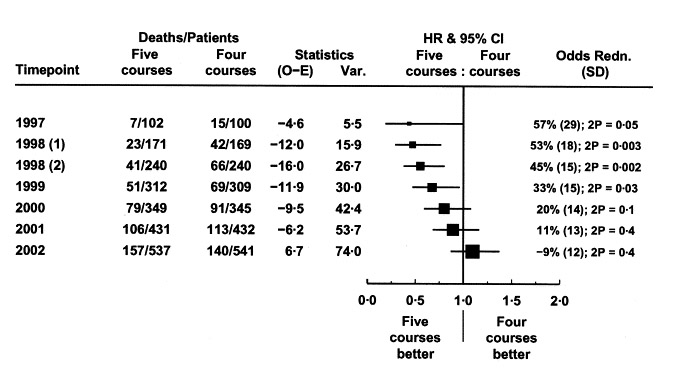
They now conclude it was “a remarkable fluke”. Why didn’t they recommend stopping for benefit at the time? The DMEC had no stopping rule – a guideline agreed at the outset about the results that would trigger a recommendation to stop the trial. They had come to the decision that it was clinically implausible for an extra course of treatment to have such a dramatic effect:
Quite extreme chance effects can and do happen more often than many clinicians appreciate. At any one time, there are hundreds, if not thousands, of trials ongoing, often with analyses at several time points and with a number of subgroup analyses. Thus it is inevitable, with all these multiple comparisons being undertaken, that highly significant results (p<0.002) will sometimes occur by chance and that conventionally significant (p<0.05), but spurious, differences will occur frequently. Taken in isolation, these may well appear so striking to investigators that it will be difficult to believe that these are chance findings. No trial is immune from such random effects, no matter how well designed and conducted.
(More on this problem with multiple comparisons at Statistically Funny – and here’s an explanation of p values.)
Our next story takes us to the Netherlands, and a trial on preimplantation genetic screening (PGS) in IVF. The results of uncontrolled studies had suggested this could result in more viable pregnancies. Willem Annkum and colleagues tell the story behind this one.
The DMC had decided to do one interim analysis at the halfway point. There was a clear difference in pregnancy rate that was significant at p<0.05 – but they had set a pre-set stopping rule requiring it to be much higher than that to end the trial early. They recommended the trial continue.
The outcome of that trial was not what people had expected: the women in the PGS group had a lower pregnancy rate. If the trial had been stopped early, some more women who had enrolled in the trial would have given birth. However, Annkum points out, the result “would have been dismissed by the protagonists of PGS as unacceptably flawed”, and maybe even more women would suffer. (There have been more trials since – and IVF with PGS continues to have lower pregnancy rates than IVF without it.)
Concern about clinicians who had strong convictions was part of the dilemma faced by the hormone therapy trials’ DSMB in the Women’s Health Initiative (WHI). The drama of the announcement that hormone therapy increased the risk of breast cancer was matched by the drama behind the scenes leading up to it.

Janet Wittes and colleagues from the WHI’s DSMB tell this story – and it’s gripping (PDF). They met every 6 months:
We agonized about the balance of our obligations to the participants in the study and to the larger public because our recommendations could adversely affect either…When an intervention like estrogen therapy, called in those days ‘hormone replacement therapy’, is widely accepted only unequivocal evidence will change clinical practice.
Tough decisions, divided opinions inside the Board, and struggles with the trials’ sponsor (the NIH) – this is a powerful account that makes it clear that even stopping trials for major unexpected harm is not remotely simple.
The WHI experience also underlines how much we owe the participants of trials. Wittes reports, “few women stopped participation as a consequence of being informed of the newly observed risks”. A trial of AZT for HIV found that in 1990, too, when other trials were stopping early for benefit. Michael Simberkoff and colleagues report that when they decided to re-approach the participants, 74% chose to continue.
But according to a systematic review of the literature on data monitoring practices as of 2001, research participants usually aren’t informed about what’s going on unless a trial is stopped. That sharpens the need for DMCs to include a community representative, although that’s probably not common.
Only a few percent of trials are stopped early for benefit, harm, or futility. They don’t always leave a mess behind them, of course. Dirk Bassler and the niftily named STOPIT-2 Study Group did a systematic review of trials stopped early for benefit compared with other trials in systematic reviews with them that were not stopped early. The interrupted trials had larger effect sizes. They argue that the practice of stopping trials early for benefit is skewing the literature, giving an exaggerated impression of effectiveness.
Steven Goodman writes that this is not so different from studies that are too small, even when they run their course. If the trial’s question is about superiority – is this option better than that one? – then maybe, he says, the desire for a precise estimation of effect size is in conflict with what the volunteers signed up for.
Goodman points out that we don’t know for sure whether a more precise estimate really will have a big impact on people’s decisions. We need to know more, he argues – not just about these questions, but about the values of society and trial participants on these issues. Regardless of how good we get at developing monitoring methods that factor in plausibility and other complexity, the decisions faced by DMCs and everyone else involved in continuing or stopping a trial will remain an extraordinarily difficult judgment call.
And so what about the SPRINT trial that has stirred up so much fuss this month? Why was it stopped? What’s now up in the air – and where does that leave people with high blood pressure?
… Continued in Post-SPRINT Trial Headaches

My Statistically Funny primer on stopping trials earlier: AGHAST! The Day the Trial Terminator Arrived. Despite my joke here about monitoring police, DMCs actually only have an advisory role – not the power to terminate a study.
And another thing – that craze for acronyms for trials like SPRINT has a downside: here’s a short cartoon post from me on that.
The cartoons are my own (CC-NC license). (More at Statistically Funny and on Tumblr.)
Data on “a remarkable fluke” from Keith Wheatley and David Clayton (2003). Be skeptical about unexpected large apparent treatment effects: the case of an MRC AML12 randomization. Controlled Clinical Trials 24: 66-70.
Montage on the stopping of the Women’s Health Initiative estrogen and progestin trial in 2002 created with: NIH Press Release (PDF), New York Times, Sydney Morning Herald, and S. Brown (2012) Shock, terror and controversy: how the media reacted to the Women’s Health Initiative, Climacteric 15: 275-280 (PDF).
* The thoughts Hilda Bastian expresses here at Absolutely Maybe are personal, and do not necessarily reflect the views of the National Institutes of Health or the U.S. Department of Health and Human Services.