Good Enough? Editors, Statistics & Grant Peer Review

Over 500 science journal editors, publishers, and meta-researchers are gathered in Chicago for the 8th Peer Review Congress (#PRC8), a once-every-4-years researchfest about “enhancing the quality and credibility of science”. I’m live-blogging – you can catch up on what happened on Day 1 here. Abstracts for Day 2 (11 September) are now online too.
Last up for the day, the EQUATOR Lecture: Patrick Bossuyt, on 15 years of STARD – standards for reporting tests of diagnostic accuracy. There are 3 basic questions:
- Is the test trustworthy? (Is it the same when different people use it?)
- Is the test meaningful? (Which is about clinical performance.)
- Is the test helpful? (About clinical effectiveness.)
Early on in his interest in diagnostic accuracy studies, Bossuyt found that it wasn’t even common for a study to tell you who the patients actually were. When a group started to score study quality, they had to sit in different rooms because they were cursing so much in frustration as they struggled through studies!
By January 2003, the STARD guidelines were published in 24 journals. After 10 years, there was some evidence from before and after studies that things were improving. Here’s a systematic review of the studies.
Bossuyt says you shouldn’t just measure reporting guidelines by the number of items reported in articles: the spread of the term “diagnostic accuracy study”, for example, or use of flowcharts, were important evolutions that sprang from STARD. It wasn’t necessarily caused by STARD, said Bossuyt, but it was part of a change for the better.
And a final important take on the day:
Last keynote of the day:
Steve Goodman summed up the state of statistics in the medical literature:
Widespread misunderstanding, misreporting, misapplication, misuse, miscalculation, and misinterpretation.

Not a new problem! Goodman talked about this paper from 1964:

Back then, they were thinking about the implications of computers:
A significant amount of misinformation could be disseminated rapidly….
But there’s still a long way to go to get strong statistical review at biomedical journals. Statistical societies internationally are created a pool of methodologists for a large scale assessment of the use of statistics in the biomedical literature! And then try to work out what model of statistical review actually works. Whoa! Watch out for this one: the project is called SMARTA.
Goodman ended back at Doug Altman‘s fabulous 1998 paper – which is available free online here:
As a final comment, I would summarize reviewing medical papers as difficult, time-consuming, sometimes interesting, sometimes boring, appreciated by journals, appreciated by authors (but perhaps not appreciated by employers), usually unpaid, occasionally frustrating, and educational. Many journals are desperate for expert statistical help. I recommend statisticians to try it.
Then we were back for the Grant Peer Review session…
João Martins got us started, with a look at the Swiss National Science Foundation. There’s about a 50% success rate for grant applications there. Applications get scored by about 3 peer reviewers. Applicants can choose one of them: for them, “there is a surplus of excellent scores”. That was stopped in 2016. There’s a disparity in grant success for women: they “cannot exclude a bias against female applicants”. The SNSF also now prefers international peer reviewers to Swiss ones, to reduce conflicts of interest.
François Delavy and colleagues also had a poster on the gender issue at SNSF. You can click to see a larger version of it here:
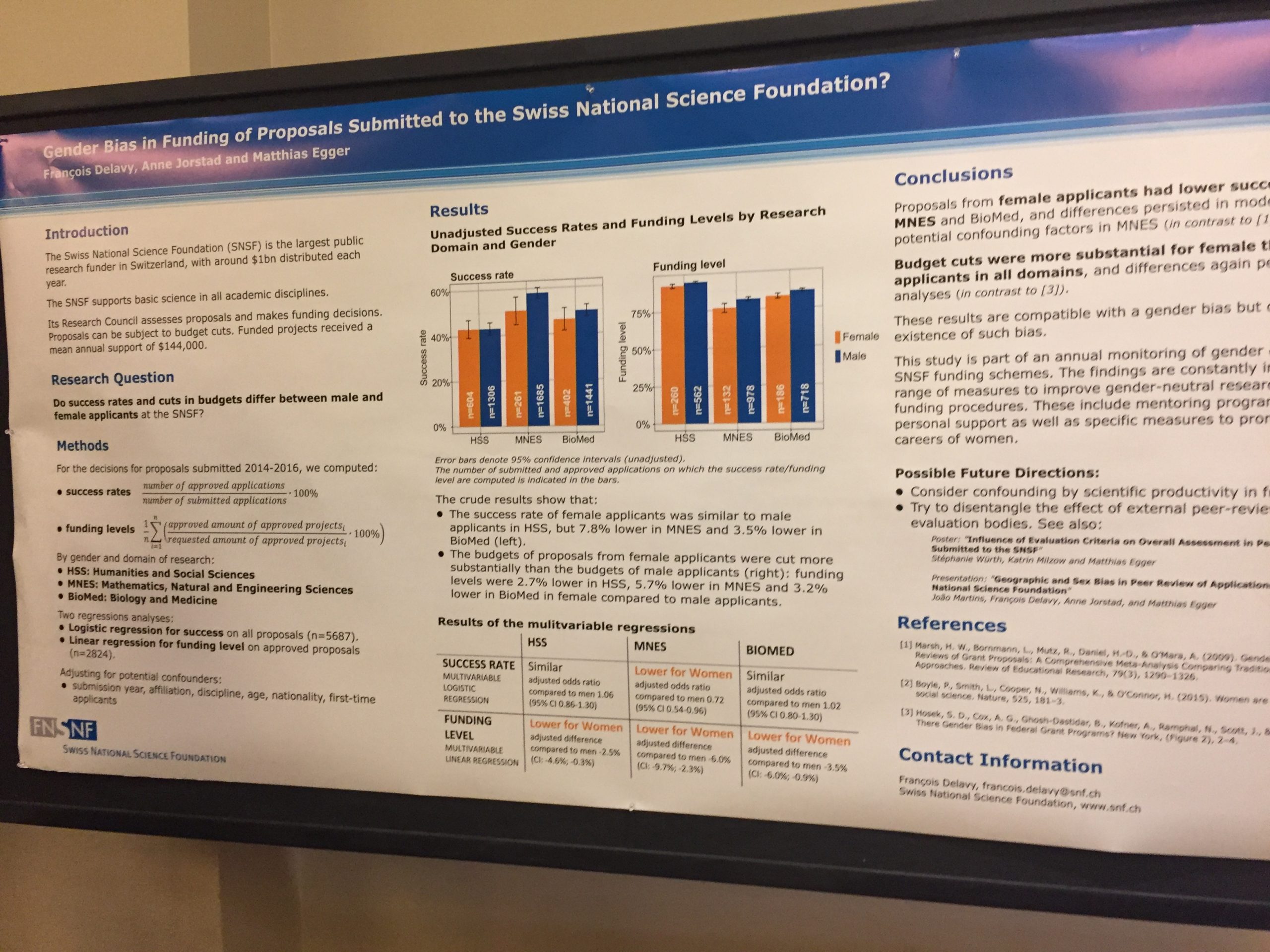
Then we were off to the NIH Center for Scientific Review (CSR) supports NIH’s grant application review process. Mary Ann Guadagno told us they typically have 17,000 peer reviewers a year. (Gulp!) They did a survey of reviewers, as well as the program officers who support the process. Focus groups were held with applicants and directors of institutes. There was concern about peer reviewer expertise, and reviewer burden.
According to the director of the CSR, Richard Nakamura, the overall success rate for applicants to the NIH currently is 18%. (There was some talk of migrating to Switzerland!)
Grant applicants unhappy with their scores apparently often appeal/complain about their scores: I would be really interested to know the gender breakdown of the appeals.
Nakamura spoke about how the NIH uses to distribute about US$25 billion a year. They moved from a 40-point scale to 9-point one in 2009. They’ve looked at ranking, and at allowing a half a point to be added or subtracted after discussion. You can see how these 2 methods affected the scoring on page 40 of the abstracts. They are going to move on to a real life test of the “half point” method.
Then on to PCORI, which includes patients and caregivers in the grant application review process: Laura Forsythe presented on 5 grant cycles (2013-2015). There were 1,312 applications: success rate was 9%.
Scores changed at least 50% of the time for all 3 reviewer types…The scores converged after discussion.

That’s it for the little tour of science grants world!
After lunch there was a session on Trial Registration…
An-Wen Chan and colleagues looked at all the trials approved by ethics committees in 2 regions of Finland, in 2 years: 2002 and 2007. Their paper about this was published today. The proportion of trials in 2002 was zero, so there was a lot of improvement – but there’s a long way to go:

Trish Groves talked about an ethics committee where ethics approval is dependent on trial registration. Chan said the same happens in Toronto, but it’s not widespread. Groves stressed the importance of the “ethical underpinning” of trials registration:
People think it’s red tape, it’s bureaucracy: it’s not.
Chan and colleagues are developing easier tools for meeting the standards of the SPIRIT guidelines.
What about the FDA regulation mandating trial registration for drug approval? Can we see whether there might have been an impact? Constance Zou and colleagues tackled this, by looking at 37 new drugs approved by the FDA between 2005-2014.
There were 142 studies in the approval packages, of which 101 were published before the FDA regulation, and 41 after. After the FDA regulation, 100% were published. For these drugs, though, 100% of the positive ones had been published before the regulation anyway. It’s early days, and this was a post-hoc analysis, but in this example at least, regulation might have an impact on the visibility of trials that don’t show particular benefit. Fingers crossed this is happening widely!

Meanwhile, over at Clinicaltrials.gov, Rebecca Williams reported on how clinical trial results reporting there is going: they only found publications in PubMed for 23% of the trials. They overlapped with the timing of the regulation. And they only searched PubMed: they could find them when they had the trials registration numbers in the abstracts, or the sponsors could add them to the registry, and they searched PubMed too.
Zou and her team used Google Scholar to hunt for publications as well PubMed.
Back from coffee break, for the session on “Quality of the Scientific Literature”.
Harold Sox and colleagues have taken on the challenge of working out markers of high quality for comparative effectiveness research that PCORI funds – including its “patient-centeredness”. They have candidate predictors: “Some predictors are easy to assess, like the principal investigator’s publication record”. Hm…
Other candidates include whether or not methodological standards were met – like, how well did they manage missing data? They also rated an initial group of 5 studies using USPTSF criteria – their quality was “fair”. I wonder what would happen, if instead of looking at things like authors’ H index, all their publications got this kind of rating?
Matthew Page and colleagues tackled statistical practices in meta-analyses with a 61-item checklist. (A post from me on some basics.)

Page’s study looked at a random set of 300 systematic reviews (SRs) published February 2014 (from this study).
Sometimes, Page said,
…they could have been slicing and dicing the studies opportunistically, but they never really gave a clinical rationale…
Many authors who do systematic reviews have limited statistical expertise and no access to it.
User-friendly software is making it easy for people to do meta-analyses without adequate skill. What kind of problems showed this? 25% claimed there was no publication bias based on weak evidence.
Mark Helfand suggested journals could consider guidance on statistical models for meta-analyses. What about Cochrane, asked senior editor at Cochrane, Toby Lasserson, nervously? Page wasn’t all that reassuring: the Cochrane Handbook deals with these issues, but every systematic reviewer is clearly not reading it as avidly as some of us do!
Marc Dewey, from the journal Radiology, warned us he would have depressing news: and he delivered! Checklists for reporting guidelines are compulsory now – but only half the peer reviewers surveyed didn’t think it was useful for peer reviewing.
It was clear that some authors just pay lip service to ticking off the items on the checklist. Maybe we could consider shorter checklists, he wondered? And authors need to use them early in their projects, not late in the editorial process: and it needs a process of education.
Jeannine Botos is scientific managing editor at JNCI, a cancer journal that rejects more than 75% of the manuscripts they get. They added a question to the manuscript submission system asking if the authors used any standard reporting guideline: terrific!
Out of 2,209 manuscripts, the authors of 52% said yes, they did. Manuscripts that used the guidelines weren’t more likely to get accepted for publication:
Using reporting guidelines did not appear to improve the clarity of presentation.
Mark Helfand responded:
It’s reassuring to hear that people can adhere to the reporting guidelines and not lose clarity.
The great Emily Sena from CAMARADES up next, with a randomized trial of the ARRIVE guidelines, for improving reporting of animal studies:
Endorsing does not equate with enforcing.
They studied in vivo research submitted to PLOS One, and the authors didn’t know about it – people who submit to the journal provide blanket consent to participating in research, and the editors and peer reviewers didn’t know it either. Sena’s group blinded outcome assessment, so assessing the quality of papers wasn’t influenced by assessors’ bias about the ARRIVE guidelines. Each paper got duplicate assessment. The intervention was being sent an ARRIVE checklist. 662 manuscripts were accepted for publication. Excellent trial – we need more like this!
….Drum roll….
Just providing a checklist, with zero extra effort, didn’t make a difference. There was, she said, “limited comprehension about what is being asked” – by both authors and peer reviewers.

First session of the day: The quality of research reporting in journals…
Robert Frank is from the School of Medicine at the University of Ottawa. He and his colleagues wanted to see whether you learn anything about an study’s quality by looking at its journal-level metrics or whether it adhered to the STARD (called Star “D”) reporting guidelines for diagnostic accuracy studies. No, it didn’t. (Surprise, surprise!)
Surrogate variables such as impact factor, adherence to STARD, are not associated with primary results of the truth – at least as established by meta-analyses.
Malcolm McLeod raised the question of whether article-level metrics have to be shown to be reliable – nothing there either. There’s no known shortcut!
Sarah Daisy Kosa and colleagues looked at discrepancies between reports of trials on trial registries and publications. They looked at 200 articles in 5 high-impact journals. Discrepancies weren’t as bad as some other studies have found – but still a depressing sight: “somewhat discouragingly, it did not get better in time”.

Lisa Bero pointed out showing the discrepancy in declaring industry funding was a new one – and definitely a worry.
An-Wen Chan pointed out that the rate of post-registration instead of pre-registration was awfully high (about a third), given that these journals are supposed to require pre-registration. Kosa said that some of the trials had started very long ago, and that has contributed. Doug Altman suggested that updating your trial protocol is analogous to updating your protocol, and you could use the CONSORT guidelines to do it.
Me: Hoping we get some better news soon, guys!
Well, there was some good news (and bad news) in the next presentation, by Cole Wayant and Matt Vassar. They looked at the quality of reporting in systematic reviews in clinical practice guidelines for 3 areas: a couple had fairly good systematic reviews, so there’s that. But the guidelines themselves did not report enough about how they were developed and who developed them.
A good time for an “ad” break: if you don’t already know the EQUATOR Network, check out the wide range of reporting guidelines. (Disclosure: I participated in developing one of them.)

Ah – good news, from Kaveh Zakeri, University of California, San Diego. An improvement in phase 3 clinical trials from the National Cancer Institute across the decade 2007-2017. They couldn’t get all the data they needed for all the trials – they chased down protocols from the authors “in some cases begging and pleading”, but still couldn’t get 13% of them.
The good news was that there was less of a problem with under-sized trials from what Zakeri called “optimism bias”: believing an intervention is more effective than it is. That means that trialists calculate that a smaller number of people is needed to get a reliable answer.
Patrick Bossuyt said he really didn’t think was necessarily “optimism bias” though: many things could contribute to people’s hypotheses. The principal investigator might be very optimistic – “The statistician might be more cynical and think most treatments won’t work anyway!”
First up, David Moher asks “Are editors and peer reviewers good enough?”, sums up early – “No and no!” – and endorses Drummond Rennie‘s 1986 comment:

Moher talked about the core competencies editors of journals need: a paper is out now. Working out what the core competencies is, he argues, a starting point for developing training for editors. (Disclosure: I was one of the peer reviewers for that article.)
What about peer reviewers?
In my institution, there is no formal training for peer reviewers…Most people do want training…But we have no evidence that these programs are effective for what they set out to do…We need to do better by authors and readers.
Training, Moher says, must be online, self-paced, and “truly” rewarded. He’s an advocate for certification for peer reviewers, too.
~~~~
Cartoons are my own (CC BY-NC-ND license). (More cartoons at Statistically Funny and on Tumblr.)
* The thoughts Hilda Bastian expresses here at Absolutely Maybe are personal, and do not necessarily reflect the views of the National Institutes of Health or the U.S. Department of Health and Human Services.