There are several reasons to buy Helen Pearson’s excellent new book, Beyond Belief: How Evidence Shows What Really Works—whether you want to…
5 Tips for Understanding Data in Meta-Analyses
There’s a deluge of scientific studies of all sorts – thousands every day. There’s often a few studies looking for answers on the same topic, but there can be dozens or even hundreds of them. Meta-analysis is a group of statistical techniques that enable data from more than one study to be combined and analyzed as a new dataset.
Meta-analysis didn’t start to spread until the 1970s. Now there are dozens of publications with meta-analyses every day and it takes less than 5 years for the number published in a year to double.* Meta-analytic methods are still a bit of a mystery to many people, though.
I’ve written a couple of “5 things” posts about meta-analysis, but not enough explaining data basics. So here’s the prequel!

This cartoon is a forest plot, a style of data visualization for meta-analysis results. Some people call them “blobbograms”. Each of these horizontal lines with a square in the middle represents the results of a different study. The length of that horizontal line represents the length of the confidence interval (CI). That gives you an estimate of how much uncertainty there is around that result – the shorter it is, the more confident we can be about the result. (Explainer here.)
The square is called the point estimate – the study’s “result” if you like. Often, it’s sized according to how much weight the study has in the meta-analysis. The bigger it is, the more confident we can be about the result.
The size of the point estimate is echoing the length of the confidence interval. They are two perspectives on the same information. Small square and long line provides less confidence than a big square with a short line.

The diamond here is called the summary estimate. It represents the summary of the results from the 3 studies combined. It doesn’t just add up the 3 results then divide them by 3. It’s a weighted average. Bigger studies with more events count for more. (More on that later.)
The left and right tips of the diamond are the two ends of the confidence interval. With each study that gets added to the plot, those tips will get closer together, and it will move left or right if a study’s result tips the scales in one direction.
The vertical line in the center is the “line of no effect”. If a result touches or crosses it, then the result is not statistically significant. (That’s a tricky concept: explainer here.)
Note from 2022: This cartoon kicked off another of my discussions, about communicating uncertainty, at my weekly newsletter.
In biomedicine, forest plots are the norm. But in other fields, like psychology, the results of meta-analyses are often presented as tables of data. That means that each data point – the start and end of each confidence interval, and so on – are numbers in a column instead of plotted on a graph. (Here’s a study that does that.)
It’s harder work to interpret the tables and easy to lose your way in the detail. On the other hand, data visualization can give a quick, strong, and false impression. It’s worth getting a good handle on the details. Here are my top 5 tips for getting some reasonable perspective. I’ll use meta-analysis of clinical studies comparing two groups because that’s so common.
1. Don’t jump to conclusions without looking carefully at the context and perspective.
Look for the specific topic and statistical measure. In the fake example below, the subject is a screening test’s results on something – it could be hospital stays, or heart attacks, for example.
The vertical line for “no effect” here is 1. For another measure it would be 0. It’s 1 because the statistical measure is a RR (risk ratio): “95% CI” is the level of significance for the confidence interval. (Here’s the explainer again.) There’s a second, dotted vertical line here: it’s showing you where the average of the combined result lies.
Except for the first one, these imaginary studies are pretty much equal. That first study, though, doesn’t have much power. The confidence interval for it is so long, the left end doesn’t even fit in the plot – it’s off the charts, if you like, and not in a good way! That’s why it has an arrow: it keeps going out of the space you can see.
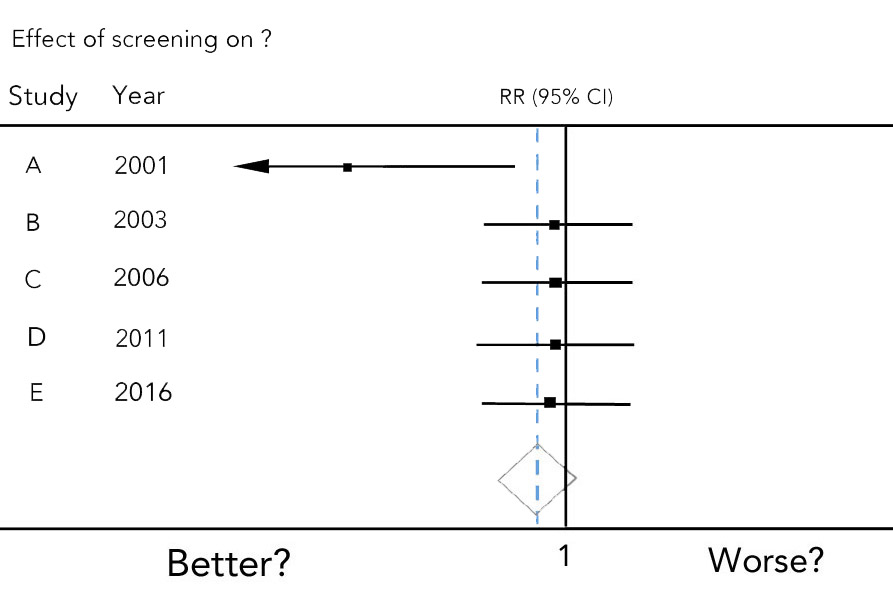
What’s on the left and what’s on the right isn’t always the same. It is chosen by the people doing the meta-analysis – and so is the way they framed the topic. How these work together is usually easy and obvious, but not always.
For example, here is one where the control group is on the left in a meta-analysis – and being on the right is the better outcome. (It’s about reducing portion sizes, and less is better.) While in this one, the control group (placebo) is on the right, and results on the left are better. (It’s about non-prescription artificial tears for dry eye symptoms.) Meanwhile in this one, in a meta-analysis on page 58 “favors” immunotherapy is on the right and it’s on the left in one on the next page. That’s not unusual.
The rank of the studies varies, too. Here, the studies are in chronological order. They can be in alphabetical order by the name given to the study – which makes it easy to find extra information from another table or meta-analysis in the paper. They can also be ranked by the results.
There isn’t always a summary of the estimate at the bottom of a forest plot of studies. So don’t think the bottom result is “the” one. And you can have forest plots that have different meta-analyses in them. For example, one displaying the summary estimates from a group of meta-analyses on related questions.
2. Don’t lose sight of what data is not in the meta-analysis.

This is probably the most common trap people fall into with meta-analysis: not keeping in mind that they are often looking at a subset of results. If the people who collected the original data didn’t measure the same thing, in much the same way, then you don’t have data you can combine from each study.
Here’s a dramatic example of that. It’s from the systematic review of over-the-counter (non-prescription) artificial tears mentioned above.
There are 2 outcomes here, comparing the mean difference in symptom scores after 21 or 28 days (the top one) and 56 days.
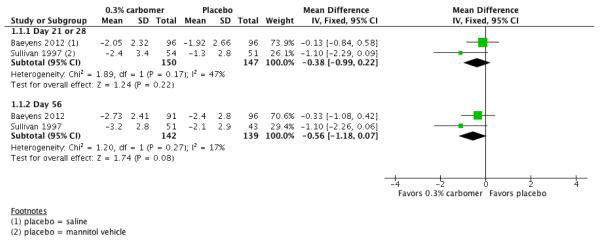
There are only 2 trials here. There were 43 trials on the effects of artificial tears, though. It’s common for everyone to focus on and report the meta-analysis data as though the summary result comes from all the studies: “A study of 43 trials of artificial tears found….” (More on this with a real-life example of that here.)
Then there’s the question of how the studies were found and chosen. A meta-analysis is not necessarily a systematic review, with a careful and thorough search for the evidence on a question. There are always 2 levels to keep in mind:
- Were the relevant studies likely to be found? and
- Which of those does this particular meta-analytic result represent?
3. Remember to check if there are signs that the studies might be too different in some way.
Just because you can throw a bunch of numbers into one mathematical pot, it doesn’t mean they all belong in the same calculation. That’s not always as obvious as it is in this sign, unfortunately!

An important concept in meta-analysis is study heterogeneity – a way of saying, “these things may not be exactly the same”. Heterogeneity can come because of something you know – such as, one trial is in children and the other is in adults. But there is unexplained heterogeneity, too, and that can be a worry. Differences in results between groups and conflicting studies can be caused by chance, and they can be caused by heterogeneity, too. (Explainer here.)
There are statistical tests for heterogeneity in meta-analyses. A common test is the I2, and it provides a percentage result. Here’s one on the top line – the I2 percentage is at the end:

It’s from the meta-analysis on page 58 mentioned earlier. It combines ratings of atopic dermatitis/eczema from 6 studies of specific allergen immunotherapy to prevent it. Just jump straight to the percentage at the end: 19%. That’s on the low end of the scale: up to 40% is probably not a concern. But 75% or more would be a lot, and make you cautious about the result. (It’s more important when the studies are powerful, because this statistical test isn’t as reliable on small samples.)
(The statistical test in the middle line up there is the test for statistical significance.)
4. See if one (or a few) results are carrying most of the weight.
The weight a study gets is related to what’s called the study’s precision. The amount of precision depends on how many participants and events were in the study. It’s not just the overall size of a study that matters.
Say the event you’re interested in is heart attacks – and you are investigating a method for reducing them. But for whatever reason, not a single person in the experimental or control group has a heart attack even though the study was big enough for you to have expected several. That study would have less ability to detect any difference your method could have made, so the study would have less weight.
It’s very common for 1 or just a couple of studies to carry a lot or even most of the weight. A study by Paul Glasziou and colleagues found that the trial with the most precision carried an average of 51% of the whole result. When that’s the case, you really want to understand that study.
Some studies are such whoppers that they overpower all other studies – no matter how many of them there are. I call them Hulks. Hulks might never be challenged, just because of their sheer size – no one will do another study like it again. Which is great when they provide a definitive answer. But not so great when they might not be representative.

The size of the point estimate and length of the CI are clues to the weight of a study. The meta-analysis might also include a percentage to show how much each individual result contributes to the weighted average. If it doesn’t, see if there’s a study or 2 much closer to the summarized result than all the others. (Tip: the dotted vertical line helps with this, if it’s been provided.)
Here’s what an actual, extreme version of that looks like – the Women’s Health Initiative (WHI) trial testing long term hormone (menopausal) therapy on breast cancer. It’s a classic “Hulk”: a 15-year research program with more than 160,000 women.
This is analysis 6.3.3, from Jane Marjoribanks and colleagues’ meta-analysis (2012 version). (There are many more meta-analyses in there than this one.)
WHI’s 140 events in over 16,000 women smash the 4 events in 2 previous much smaller trials. WHI carries 95.4% of the weight in the summary estimate:
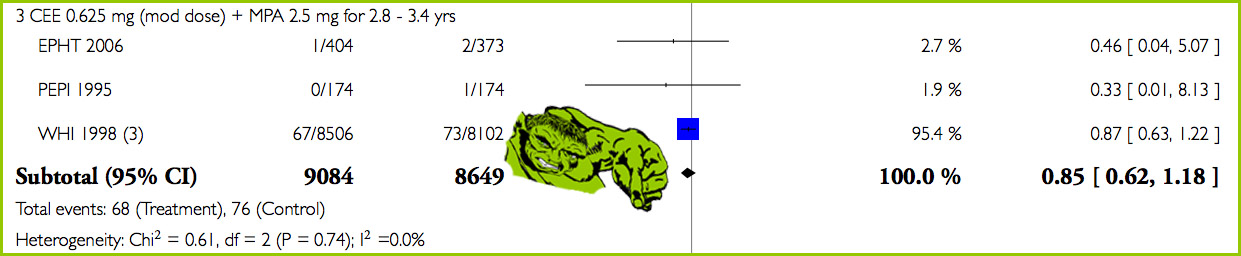
Tip: If you get confused by the statistical measure and need to gain some perspective on what happened, you will often see raw numbers for events. Here they are over on the left: 68 out of 9,084 women had breast cancer in the treatment groups (the left column) and 76 out of 8,649 in the control groups. It’s touching the line of no effect, so it’s not a statistically significant result.
5. Size isn’t everything – and be careful of “vote counting”.
One of the reasons meta-analysis is valuable is because it’s a more reliable alternative than “vote counting”: “4 out of 5 studies show….”
What if the “4” here are all small, badly conducted studies in a group that’s not even relevant to you – and the fifth is the only good, powerful, relevant trial?
Naive vote counting is risky, the more studies there are: “it can lead to disastrous conclusions under many circumstances”, write Madden and Paul.
Here are 2 meta-analyses from a systematic review about peer review in biomedical journals. There is a combined summary estimate for the 2 analyses as well. I’ve stripped away the context, but left a critical extra element to the right:

Even though the summary estimate at the bottom favors un-blinded peer review, there is no definitive answer here. Those colored circles on the right are showing assessments of the risk of bias according to 4 criteria, and they help show why.
Only 1 study – the top one – gets a green “thumbs up” for all 4 criteria on an outcome, but it doesn’t have much precision. The second study has more precision on that question, but it has a couple of yellow question marks….
This display makes a point of how much judgment and complexity there is here. One study more or less. A difference in judgment about study quality. Focusing on different outcomes or questions. Any of those can change the result.
A good systematic review and meta-analysis can be a great help in sorting out apparently conflicting studies. But it’s no wonder that the results of meta-analyses themselves can vary. We need more people to be able to read them critically, and to see why meta-analyses become conflicting results themselves.

You can keep up with my work at my newsletter, Living With Evidence. And I’m active on Mastodon: @hildabast@mastodon.online
~~~~

And what are they actually measuring? Check out my 6 Tips for Deciphering Outcomes in Health Studies.
If you would like to read a more technical introduction to interpreting forest plots, check out this one from Philip Sedgwick. And for doing a systematic review, check out Judith Anzures-Cabrera and Julian P.T. Higgins’ paper on graphical displays for meta-analysis (2010).

My original meta-analysis posts (there is some repetition):
5 Key Things to Know About Meta-Analysis – basics
Another 5 Things to Know About Meta-Analysis – traps
All my posts tagged meta-analysis.
The New Cuyama, California town sign is by Mike Gogulski via Wikimedia Commons.
The cartoons are my own (CC BY-NC-ND license). (More cartoons at Statistically Funny.) And you can keep up with new posts and more discussions via my newsletter.
My estimate of the rate of doubling of meta-analyses published in a year was based on this search in PubMed on 2 July 2017 – a shortcut is to check out the “Results by year” data shown on the right. (Back to top)
* The thoughts Hilda Bastian expresses here at Absolutely Maybe are personal, and do not necessarily reflect the views of the National Institutes of Health or the U.S. Department of Health and Human Services.